要说 2024 年 Node.js 的 ORM 框架应该选择哪个?毫无疑问选 Prisma。至于为何,请听我细细道来。
本文面向的对象是饱受 TypeORM 折磨的资深用户(说的便是我自己)。只对这两个 ORM 框架从开发体验上进行对比,你也可以到 这里 查看 Prisma 官方对这两个 ORM 框架的对比。
整体对比
更新频率 & 下载量
TypeORM 距离上次更新已经过去半年之久了(下图截取自 24 年 1 月 1 日,没想到年初竟然还复活了)

从下载量以及 star 数来看,如今 Prisma 已经超过 TypeORM,这很大一部分的功劳归功于像 Next.js、Nuxt.js 这样的全栈框架。
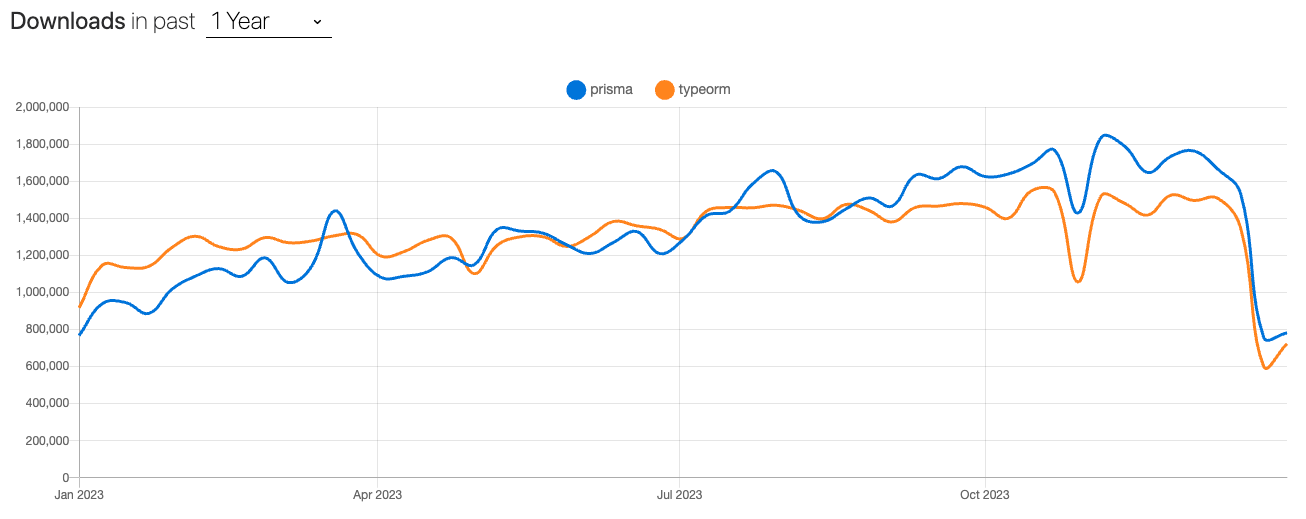
上图来源 https://npmtrends.com/prisma-vs-typeorm
而在 Nest.js 的 Discord 社区 讨论之中,Prisma 也成为诸多 Nest.js 开发者首选的 ORM 框架,因为它有着更好的开发体验。
在大势所趋之下相信你内心已经有一份属于自己的答案。
文档 & 生态
从文档的细致程度上 Prisma 比 TypeORM 要清晰详尽。在 Get started 花个数十分钟了解 Prisma 基本使用,到 playground.prisma.io 中在线尝试,到 learn 查看官方所提供的免费教程。
此外 Prisma 不仅支持 js/ts 生态,还支持其他语言。丰富的生态下,加之 Prisma 开发团队的背后是由商业公司维护,无需担心需求得不到解决。
开发体验对比
在从开发体验上对比之前,我想先说说 TypeORM 都有哪些坑(不足)。
findOne(undefined) 所查询到的却是第一条记录
首先 TypeORM 有个天坑,你可以在 这个 Issue 中查看详情或查看 这篇文章 是如何破解使用 TypeORM 的 Node.js 应用。
当你使用 userRepository.findOne({ where: { id: null } }) 时,从开发者的预期来看所返回的结果应该为 null 才对,但结果却是大跌眼镜,结果所返回的是 user 表中的第一个数据记录!
你可能会说,这不是 bug 吗?为何官方还不修。事实上确实是 bug,而事实上官方到目前也还没修复该 bug。再结合上文提到的更新频率,哦,那没事了。
目前解决方法则是用 createQueryBuilder().where({ id }).getOne() 平替上一条语句或者确保查询参数不为 undefined。从这也可以看的出,TypeORM 在现今或许并不是一个很好的选择。
synchronize: true 导致数据丢失
synchronize 表示数据库的结构是否和代码保持同步,官方提及到请不要在生产环境中使用,但在开发阶段这也并不是一个很好的做法。举个例子,有这么一个实体
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column()
name: string
}
当开启了 synchronize: true,并且将 name 更改为 title 时,一旦运行 nest 服务后就会发现原有 name 下的数据全都丢失了!如图所示
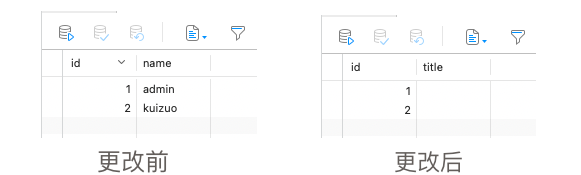
因为 TypeORM 针对上述操作的 sql 语句是这样的
ALTER TABLE `user` CHANGE `name` `title` varchar(255) NOT NULL
ALTER TABLE `user` DROP COLUMN `title`
ALTER TABLE `user` ADD `title` varchar(255) NOT NULL
也就是说,当你在开发环境中,修改某个字段(包括名字,属性)时,该字段原有的数据便会清空。
因此针对数据库更新的操作最正确的做法是使用迁移(migrate)。
接入成本
在 Nest 项目中,Prisma 的接入成本远比 TypeORM 来的容易许多。
相信你一定有在 xxx.module.ts 中在 imports 中导入 TypeOrmModule.forFeature([xxxEntity]) 的经历。就像下面代码这样:
@Module({
imports: [TypeOrmModule.forFeature([UserEntity])],
controllers: [UserController],
providers: [UserService],
exports: [TypeOrmModule, UserService],
})
export class UserModule {}
对于初学者而言,很大程度上会忘记导入 xxxEntity,就会出现这样的报错
Potential solutions:
- Is UserModule a valid NestJS module?
- If "UserEntityRepository" is a provider, is it part of the current UserModule?
- If "UserEntityRepository" is exported from a separate @Module, is that module imported within UserModule?
@Module({
imports: [ /* the Module containing "UserEntityRepository" */ ]
})
Error: Nest can't resolve dependencies of the userService (?). Please make sure that the argument "UserEntityRepository" at index [0] is available in the UserModule context.
此外这还不是最繁琐的,你还需要再各个 service 中,通过下面的代码来注入 userRepository。
@InjectRepository(UserEntity)
private readonly userRepository: Repository<UserEntity>
一旦实体一多,要注入的 Repository 也就更多,无疑不是对开发者心智负担的加深。
再来看看 Prisma 是怎么导入的,你可以使用 nestjs-prisma 或者按照官方文档中创建 PrismaService。
然后在 service 上,注入 PrismaService 后,就可以通过 this.prisma[model] 来调用模型(实体) ,就像这样
import { Injectable } from '@nestjs/common'
import { PrismaService } from 'nestjs-prisma'
@Injectable()
export class AppService {
constructor(private prisma: PrismaService) {}
users() {
return this.prisma.user.findMany()
}
user(userId: string) {
return this.prisma.user.findUnique({
where: { id: userId },
})
}
}
哪怕创建其他新的实体,只需要重新生成 PrismaClient,都无需再导入额外服务,this.prisma 便能操作所有与数据库相关的 api。
更好的类型安全
Prisma 的贡献者中有 ts-toolbelt 的作者,正因此 Prisma 的类型推导十分强大,能够自动生成几乎所有的类型。
而反观 TypeORM 虽说使用 Typescript 所编写,但它的类型推导真是一言难尽。我举几个例子:
在 TypeORM 中,你需要 select 选择某个实体的几个字段,你可以这么写
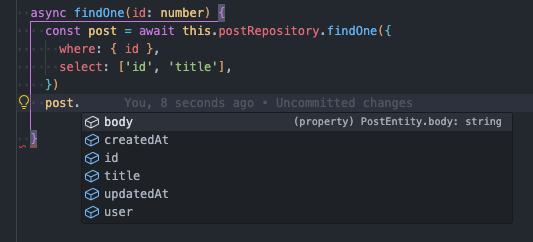
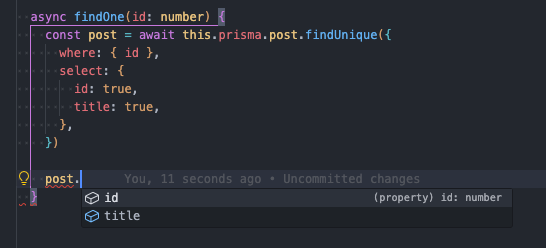
你会发现 post 对象的类型提示依旧还是 postEntity,没有任何变化。但从开发者的体验角度而言,既然我选择查询 id 和 title 两个字段,那么你所返回的 post 类型应该也只有 id 与 title 才更符合预期而后续代码中由于允许 post 有 body 属性提示,那么 post.body 为 null 这样不必要的结果。
再来看看 Prisma,你就会发现 post 对象的类型提示信息才符合开发者的预期。像这样的细节在 Prisma 有非常多。
这还不是最关键的,TypeORM 通常需要使用 createQueryBuilder 方法来构造 sql 语句来满足开发者所要查询的预期。而当你使用了该方法,你就会发现你所编写的代码与 js 无疑,我贴几张图给大伙看看。
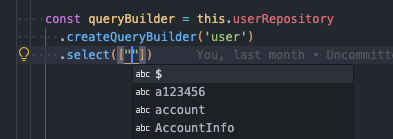
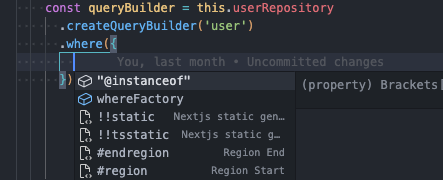
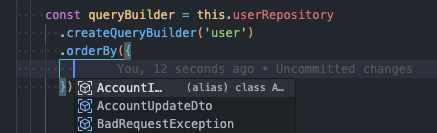
这无疑会诱发一些潜�在 bug,我就多次因为要 select 某表中的某个字段,却因拼写错误导致查询失败。
创建实体
在 TypeORM 中,假设你要新增一条 User 记录,你通常需要这么做
const newUser = new User()
newUser.name = 'kuizuo'
newUser.email = 'hi@kuizuo.cn'
const user = userRepository.save(newUser)
当然你可以对 User 实体中做点手脚,像下面这样加一个构造函数
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ unique: true })
username: string
@Column()
email: string
constructor(partial?: Partial<UserEntity>) {
Object.assign(this, partial)
}
}
const newUser = new User({
name: 'kuizuo',
email: 'hi@kuizuo.cn',
})
const user = userRepository.save(newUser)
于是你就可以传递一个 js 对象到 User 实体,而不是 newUser.xxx = xxx 像 Java 版的写法。
而要是涉及到多个关联的数据,往往需要先查询到关联数据,然后再像上面这样赋值+保存。这里就不展开了,使用过 TypeORM 的应该深有体会。
而在 Prisma 中,绝大多数的操作你都只需要一条代码语句��外加一个对象结构,像上述 TypeORM 的操作对应 Prisma 的代码语句如下
const user = await prisma.user.create({
data: {
name: 'kuizuo',
email: 'hi@kuizuo.cn',
},
})
根据条件来创建还是更新
在数据库中操作经常需要判断数据库中是否有某条记录,以此来决定是更改该记录还是创建新的一条记录,而在 Prisma 中,完全可以使用 upsert,就像下面这样
const user = await prisma.user.upsert({
where: { id: 1 },
update: { email: 'example@prisma.io' },
create: { email: 'example@prisma.io' },
})
聚合函数
在 TypeORM 中,假设你需要使用聚合函数来查询的话,通常会这么写
const raw = await this.userRepository
.createQueryBuilder('user')
.select('SUM(user.id)', 'sum')
.getRawOne()
const sum = raw.sum
如果只是像上面这样,单纯查询 sum,那么 raw 的值是 { sum: 1 } , 但最要命的就是 select 配合 getRawOne 还要额外查询 user 实体的属性,所得到的结果就像这样
const raw = await this.userRepository
.createQueryBuilder('user')
.select('SUM(user.id)', 'sum')
.addSelect('user')
.where('user.id = :id', { id: 1 })
.getRawOne()
{
user_id: 1,
user_name: 'kuizuo',
user_email: 'hi@kuizuo.cn',
sum: '1'
}
所有 user 的属性都会带有 user_ 前缀,这看上去有点不是那么合理,但如果考虑要联表查询的情况下,就会存在相同名称的字段,通过添加表名(别名)前缀就可以避免这种情况,这样来看貌似又有点合理了。
但还是回到熟悉的类型安全,这里的所返回的 raw 对象是个 any 类型,一样不会有任何提示。
而在 Prisma 中,提供了 专门用于聚合的方法 aggregate,可以特别轻松的实现聚合函数查询。
const minMaxAge = await prisma.user.aggregate({
_count: {
_all: true,
},
_max: {
profileViews: true,
},
_min: {
profileViews: true,
},
})
{
_count: { _all: 29 },
_max: { profileViews: 90 },
_min: { profileViews: 0 }
}
看到这里,你若是长期使用 TypeORM 的用户必定会感同身受如此糟糕的体验。那种开发体验真的是无法用言语来形容的。
Prisma 生态
分页
在 Prisma 你要实现分页,只需要在 prismaClient 继承 prisma-extension-pagination 这个库。就可像下面这样,便可在 model 中使用paginate方法来实现分页,如下代码。
import { PrismaClient } from '@prisma/client'
import { pagination } from 'prisma-extension-pagination'
const prisma = new PrismaClient().$extends(pagination())
const [users, meta] = prisma.user
.paginate()
.withPages({
limit: 10,
page: 2,
includePageCount: true,
});
// meta contains the following
{
currentPage: 2,
isFirstPage: false,
isLastPage: false,
previousPage: 1,
nextPage: 3,
pageCount: 10, // the number of pages is calculated
totalCount: 100, // the total number of results is calculated
}
支持页数(page)或光标(cursor)。
按页查询: 用于传统分页,例如翻页
光标查询: 根据游标进行查询,例如无限滚动
而在 TypeORM 你通常需要自己封装一个 paginate方法,就如下面代码所示(以下写法借用 nestjs-typeorm-paginate)
async function paginate<T>(
queryBuilder: SelectQueryBuilder<T>,
options: IPaginationOptions,
): Promise<Pagination<T>> {
const { page, limit } = options
queryBuilder.take(limit).skip((page - 1) * limit)
const [items, total] = await queryBuilder.getManyAndCount()
return createPaginationObject<T>({
items,
totalItems: total,
currentPage: page,
limit,
})
}
// example
const queryBuilder = userRepository.createQueryBuilder('user')
const { items, meta } = paginate(queryBuilder, { page, limit })
当然也可以自定义userRepository,为其添加 paginate 方法,支持链式调用。但这无疑增添了开发成本。
根据 Schema 自动生成数据验证
得益于 Prisma 强大的数据建模 dsl,通过 generators 生成我们所需要的内容(文档,类型),比如可以使用 zod-prisma-types 根据 Schema 生成 zod 验证器**。**
举个例子,可以为 schema.prisma 添加一条 generator,长下面这样
generator client {
provider = "prisma-client-js"
output = "./client"
}
generator zod {
provider = "zod-prisma-types"
output = "./zod"
createModelTypes = true
// ...rest of config
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id String @id @default(uuid())
email String @unique
name String?
}
执行构建命令后,这将会自动生成 zod/index.ts 文件,将包含 UserSchema 信息,其中片段代码如下
export const UserSchema = z.object({
id: z.string().uuid(),
email: z.string(),
name: z.string().nullable(),
})
export type User = z.infer<typeof UserSchema>
再通过 createZodDto,将 zod 验证器转化为 dto 类,就像下面这样
当然你可能并不想在 nestjs 项目中使用 zod,而是希望使用传统的 class-validator 来编写 dto。可以使用社区提供的 prisma-class-generator 根据已有 model 生成 dto。
合理来说,Prisma 并不是一个传统的 ORM,它的工作原理并不是将表映射到编程语言中的模型类,为处理关系数据库提供了一种面向对象的方式。而是在 Prisma Schema 中定义模型。在应用程序代码中,您可以使用 Prisma Client 以类型安全的方式读取和写入数据库中的数据,而无需管理复杂模型实例的开销。
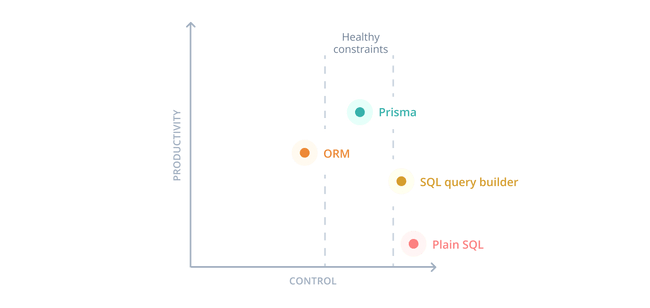
总而言之,你若想要更好的类型,简洁的实体声明语法,况且带有可视化桌面端应用,以及更好的生态完备,那么你就应该选 Prisma。
总结
在写这篇文章时,我也是彻底的将 Nestjs 项目中由 TypeORM 迁移到 Prisma ,这期间给我最大的变化就是在极少的代码量却又能实现强大的功能。许多涉及多表的 CRUD操作可以通过一条简洁的表达式来完成,而在使用 TypeORM 时,常常需要编写繁琐臃肿的 queryBuilder。
TypeORM 有种被 nestjs 深度绑定的模样,一提到 TypeORM,想必第一印象就是 Nestjs 中所用到的 ORM 框架。然而,Prisma 却不同,是一个全能通用的选择,可以在任何的 js/ts 框架中使用。
从开发体验的角度不接受任何选择 TypeORM 的反驳,有了更优优秀的选择,便不愿意也不可能在回去了。如果你还未尝试过 Prisma,我强烈建议你亲身体验一番。