挺早之前就想写个 api 接口服务,封装下自己收集的一些 api 接口,以便调用,正好最近在接触 SSR 框架,所以就使用 Nuxt3 来编写该项目。
在线地址: API-Service
开源地址: kuizuo/api-service
如果你已经了解过 Nuxt3 与运行过程,那么可以直接跳转至 实战
npx nuxi init nuxt3-app
可能会安装不上 会提示 could not fetch remote https://github.com/nuxt/starter,大概率就是本地电脑无法访问 github,这时候科学上网都不一定好使,这里建议尝试更换下网络或设置 host 文件。
安装完毕后,根据提示安装依赖与启动项目
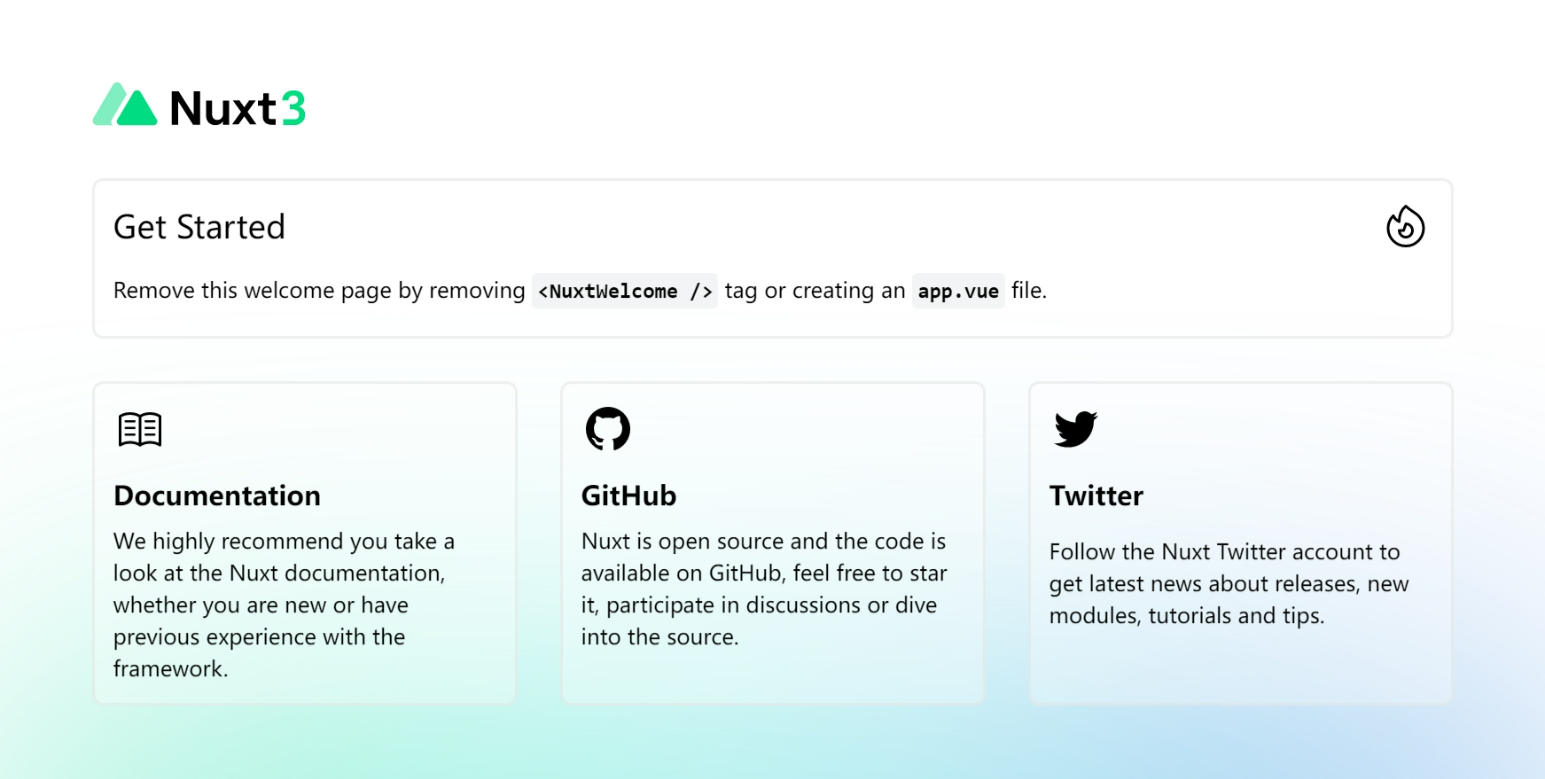
初始的 nuxt3 项目及其简单,甚至没有 page、components、assets 等目录。
关于 nuxt3 本文不做过多介绍,本文只对部分进行介绍。nuxt 已经发布快 1 年了,相信外面很多相关介绍文章。
Nuxt3 介绍
自动导入
nuxt.js 与 next.js 极其相像,但 nuxt 却精简许多,这归功于 nuxt 的自动导入,这可以让你无需导入像 vue 中的 ref 等等函数,导入组件等操作,不过前提是代码文件位置要符合 nuxt 规范。如果你尝试使用过 vite 的一些自动导入插件,其效果是一样的,只不过 nuxt 都已经配置好,开箱即用。
文件路由
pages 为 nuxt 中页面所存放的位置,会将 pages 目录下的文件(.vue, .js, .jsx, .ts or .tsx) 与路由映射,像pages/index.vue 映射为 /,然后在 app.vue 中通过<NuxtPage/> 来展示 pages。
要注意,pages 下的文件一定要有根节点,不然在路由切换的时候可能会出现问题(事实上建议所以的 vue 组件都有根节点,虽说 vue3 允许多个根节点,但或多或少存在一定问题)
至于动态路由与嵌套路由,文档说明的比较详细了,这里就不费口舌了
服务引擎
Nuxt3 中的的 api 接口服务引擎使用的是⚗️ Nitro 的 JavaScript 服务,使用的是h3的 http 框架(相当于 hook 版的 http 框架),不过文档不是特别详细,很多东西都要琢磨。(这个框架是真的相对冷门,之前都未曾听闻过)
关于 Nuxt3 的服务具体可以看 Nuxt 3 - Server Routes,这里演示部分代码
创建一个服务,创建文件server/api/hello.ts
export default defineEventHandler(event => {
return 'hello nuxt'
})
请求 http://localhost/api/hello 便可得到hello nuxt,在 event 可以得到 req 与 res 对象。不过在 req 身上是获取不到 query 和 body 的,这里需要使用 h3 提供的 hooks,如useMethod(),useQuery(),useBody()来获取,例如。
export default eventHandler(async event => {
const body = await useBody(event)
return `User updated!`
})
这与传统的 node 的 http 框架不同点就是 query,body 这些参数不是从函数的上下文(context)取,而是通过 hook 来获取,所以这就是我为什么我说这相当于 hook 版的框架。关于这些 api,可以点我查看
数据获取
定义完了接口,那必然是要获取数据的,nuxt.js 有四种方式来获取数据,不过主要就二种useFetch与useAsyncData,另外两种是其懒加载形式。
像上面定义了 helloworld 接口就可以像下面这样使用
<script setup>
const { data } = await useFetch('/api/hello')
console.log(data) // hello nuxt
</script>
<template>
{{ data }}
</template>
useAsyncData
<script setup>
const { data } = await useAsyncData('hello', () => $fetch('/api/hello'))
console.log(data) // hello nuxt
</script>
<template>
{{ data }}
</template>
至于 useAsyncData 与 useFetch 有什么区别的话,如果请求的是 url 资源,那么建议使用 useFetch,如果请求的是其他来源的资源,就使用 useAsyncData。可以说在请求 url 资源时,两者是等价的,如下
useFetch(url) <==> useAsyncData(url, () => $fetch(url))
那么如何 SSR(服务端渲染)呢? nuxt3 默认是全 SSR 的渲染模式,也就是说在上面的数据请求后就是 SSR 渲染,客户端接受到的也就是带有数据页面。
如果要使用传统的客户端渲染只需要填加一个 options 的 server 参数为 false 即可,如
const { data } = await useFetch('/api/hello', { server: false })
自己尝试下将 server 切换,然后打开控制台->网络中查看 Fetch/XHR 中是否有和数据相关的请求便可知道是在服务端发送的请求数据,还是客户端发送的数据。
实战
模板
这个项目所使用的模板是 Vitesse for Nuxt 3
该模板中集成了一些 vue 生态的相关模块(vueuse, pinia, unocss),开发者可以不必自行封装这些模块。
页面设计
页面设计的话其实没啥好说的,主要使用到了原子类的一个框架unocss。
接口转发
这里我会以通过每日一言的 api 例子来给你演示其功能实现,请求该 api 可以得到
{
"id": 5233,
"uuid": "9504a2a2-bab7-4c7d-b643-a6642ed5c55e",
"hitokoto": "人间没有单纯的快乐,快乐总夹带着烦恼和忧虑。",
"type": "d",
"from": "杨绛",
"from_who": "我们仨",
"creator": "a632079",
"creator_uid": 1044,
"reviewer": 4756,
"commit_from": "web",
"created_at": "1583786494",
"length": 22
}
这里创建server/api/one.ts文件
export default defineEventHandler(async (event) => {
const { type = 'text' } = useQuery(event)
const data = await (await fetch('https://v1.hitokoto.cn/')).json()
if (type = 'json') {
return data
}
else {
event.res.setHeader('Content-Type', 'text/html;charset=utf-8')
return data.hitokoto
}
}
这样,这个接口就已经定义完毕了,此时访问 /api/one 所得到的就是一句短语。默认状态下返回文本,如需要 json 数据等额外信息,则可添加type=json。例请求/api/one?type=json,得到的完整数据如下
{
"id": 7173,
"uuid": "49eff9ca-7145-4c5f-8e62-d3dca63537fa",
"hitokoto": "即使人生是一场悲剧,也应该笑着把人生演完。",
"type": "k",
"from": "查拉图斯特如是说",
"from_who": "尼采",
"creator": "Kyanite",
"creator_uid": 8042,
"reviewer": 1,
"commit_from": "web",
"created_at": "1614946509",
"length": 21
}
而这整个过程也就是其实也就是接口转发,将访问 /api/one 的请求转发给目标 url https://v1.hitokoto.cn/ 的过程,然后对其数据进行抽取和封装,最终展示给调用方。
然而这只是完成了接口的转发,那么接口的文档又该如何实现呢?
接口文档
要存储接口文档的数据,就需要使用 CMS(内容管理系统)或者 Database(数据库),一开始我原本打算使用strapi来作为 CMS,毕竟没尝试过strapi,而且 SSR 框架也会搭配strapi来使用,不需再自建后端。但就在我刷官方模块的时候,无意间发现个官方模块 content。简单了解了一下,发现这个模块有点意思,并且能很简单的满足我当下的需求,于是就选择使用它。也可以使用官方提供的codesandbox来尝试
不过content能实现的功能比较有限,没有strapi那么丰富,有多有限呢,基本的 CURD 只能实现查,无法增删改(至少官方文档是没有提供相应的函数)。不过content也不用像strapi那样自建一个服务,可以说是贼简洁了。
这里省略模块的导入的步骤,在根目录下创建 content 目录,目录下的文件可以是markdonw,json,yaml,csv。和 pages 一样,这里的文件都会映射对应的路由,不过这里需要映射的路由前缀是/api/_content/query/。举个例子
- content/hello.json
- output
{
"title": "Hello Content v2!",
"description": "The writing experience for Nuxt 3",
"category": "announcement"
}
{
_path: '/hello',
_draft: false,
_partial: false,
title: 'Hello Content v2!',
description: 'The writing experience for Nuxt 3',
category: 'announcement',
_id: 'content:hello.json',
_type: 'json',
_source: 'content',
_file: 'hello.json',
_extension: 'json'
}
访问/api/_content/query/hello所得到的就是 output 的内容。
这里只演示 json 数据,是因为该项目主要用到 json 数据来渲染,如果是 markdown 的话,还有一些自带的组件 ContentDoc 来展示 markdown 数据。所提供的功能可以说非常适合用于文档类,或者博客类的站点。
回到该实战本身,来说明实际数据及其如何请求,上面的例子所对应的 api 文档数据如下
{
"id": "one",
"name": "一言",
"desc": "一言指的就是一句话,可以是动漫中的台词,也可以是网络上的各种小段子",
"path": "/api/one",
"method": "GET",
"params": [
{
"name": "type",
"value": "json",
"type": "string",
"desc": "数据格式(text,json,img)",
"required": false
}
],
"dataType": "text",
"example": "/api/one"
}
然后这些数据通过 content 提供的queryContent()来获取,这里来看其渲染页面pages/apidoc/[id].vue的部分代码
<script setup lang="ts">
const { data } = await useAsyncData(id, () => queryContent(id).findOne())
const { name, desc, params, path, method, returnType, example } = data.value
// ...
</script>
获取到数据,然后渲染到 vue 上,这些就不过多叙述了。
接口限流
假设现在上线了这些接口,但是不做任何限制,那么调用方就可以无限次调用获取接口,这对服务器压力来说是十分巨大的,所以就需要对接口进行限流。
一般要做限流操作都需要涉及到中间件,在 Nuxt 中有路由中间件,和服务中间件 ,这里由于是要处理后端接口的,所以就需要使用服务中间。
创建server/middleware/limit.ts 文件
export default defineEventHandler(async event => {
console.log(`limit`)
})
这时候,只要是 Fetch 请求都将打印limit,既然请求能拦截到,那限流就简单了(其实并不简单,因为这个 h3 的文档与相关库实在是少的可怜)。
不过由于没有使用到用户鉴权等功能(在这个项目中也没打算上),所以限流的操作只有从 IP 的手段下手。这里我选用的是node-rate-limiter-flexible这个库,下面是实现代码
import { RLWrapperBlackAndWhite, RateLimiterMemory } from 'rate-limiter-flexible'
const rateLimiter = new RLWrapperBlackAndWhite({
limiter: new RateLimiterMemory({
points: 1,
duration: 1,
}),
})
function getIP(req) {
return (
(req.headers['x-forwarded-for'] as string) || (req.socket?.remoteAddress as string)
).replace('::ffff:', '')
}
export default defineEventHandler(async event => {
const { req, res } = event
if (/^\/api\/[A-Za-z0-9].*/.test(req.url || '')) {
const ip = getIP(req)
try {
await rateLimiter.consume(ip)
} catch (error) {
res.statusCode = 429
return { statusCode: 429, statusMessage: '请求太快了,请稍后再试' }
}
}
})
自行阅读代码即可,设置的限制是 1 秒内只能请求 1 条接口。
接口缓存
除了接口限流外,对于实时性不高的接口可以开启缓存,这样可以防止过度调用导致接口匮乏。并且对于重复调用的接口响应速度更快,性能更佳。
可 nuxt 的中间件好像只能拦截用户端发送的请求数据,而服务端发送的给用户端的数据貌似无法拦截,也就无法在中间件中获取到数据或者处理数据了?
是的,nuxt 的服务层并不像nest有 Middleware(中间件),Guards(守卫),Interceptors(拦截器),而这里所要拦截的部分也就是 nest 中的 Interceptors。
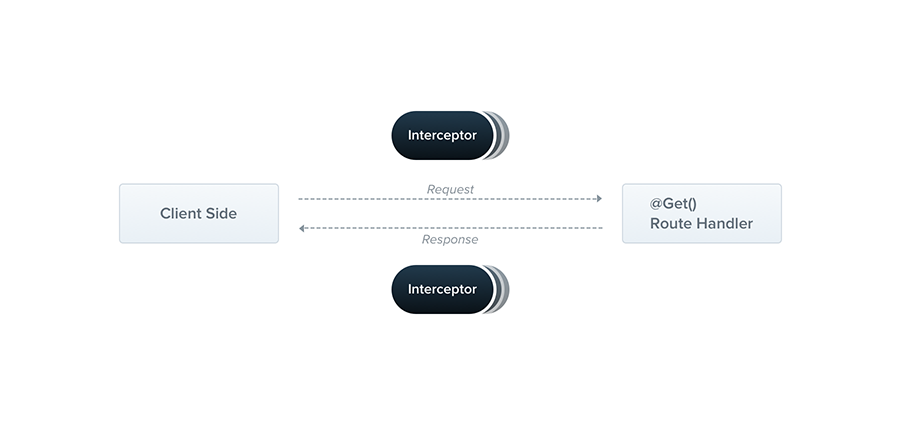
不过 nuxt 只提供了中间件,这够实现接口缓存的功能了,不过需要一些“技巧”,关于这个技巧我写过的一篇文章 JS 函数 hook 比较详细的介绍该技巧,这里简单说下。
假设有个 add 函数,我并不想破坏 add 的参数与内部代码结果,但是我又像在调用 add 函数时,查看传入的参数,以及计算的结果,那该如何做?来看下面代码
function add(a, b) {
return a + b
}
let original_add = add
add = function () {
console.log('arguments', arguments)
let result = original_add.apply(this, arguments)
console.log('result', result)
return result
}
首先重新定义了与 add 相同作用的函数,名为 original_add,然后将 add 修改,同时修改像成上面的代码。这时尝试调用 add 就可以发现输出了传入的参数及计算后的结果。
知道了这个修改 add 函数的技巧,要拦截 nuxt 的服务端数据也就不难了。只需要将这里的 add 函数替换成 http 框架的返回函数即可,也就是res.end()。大致逻辑如下
export default defineEventHandler(async event => {
const { req, res } = event
const original_res_end = res.end
res.end = function (...args: any) {
// 这里的args的第一个参数就是 res.end 调用的参数,即返回给客户端的数据
console.log(args)
// 最后可别忘了调用原始的 res.end,不然客户端一直处于等待状态
return original_res_end.apply(this, args)
}
})
这里所使用到的缓存库是lru-cache,其实现代码如下
import type { ServerResponse } from 'h3'
import { defaultContentType } from 'h3'
import LRU from 'lru-cache'
const options = {
max: 500,
ttl: 1000 * 60 * 1, // 缓存1min
allowStale: false,
updateAgeOnGet: false,
updateAgeOnHas: false,
}
const cache = new LRU(options)
export default defineEventHandler(async event => {
defaultContentType(event, 'text/plain; charset=utf-8')
const { req, res } = event
if (/^\/api\/[A-Za-z0-9].*/.test(req.url || '')) {
const key = req.url
const cached = cache.get(key)
if (cached) return res.end(cached)
const original_res_end = res.end
res.end = function (...args: any): ServerResponse {
const data = args?.[0]
if (data) {
cache.set(key, data)
}
return original_res_end.apply(this, args)
}
}
})
现在缓存是实现了,但所有的接口都被强行缓存 1 分钟,像有些接口(如随机图片)要是也这样设定,那就失去了这个接口的实时性了(我明明要随机,你却偏偏返回都是同一张图片)。所以就要对不同的接口进行不同的接口缓存处理,这里就可以使用到上下文 context。
定义接口代码
export default defineEventHandler(async event => {
event.context.cache = { ttl: 1000 * 5 } // 缓存5s
// ... 其他代码 ...
})
定义缓存代码
// ... 其他代码 ...
if (data) {
if (context.cache) {
const options = context.cache
cache.set(key, data, options)
} else {
cache.set(key, data)
}
}
这样就可以为不同的接口,设置不同的缓存配置。(不过这样还是不够优雅,其实可以上装饰器的,但是想了想这也非 AOP 设计,于是就没尝试了)
异常捕获
这个功能主要用途是有些接口可能失效了,就需要捕获这些异常接口信息然后停止或者修改该接口。如果要在每个接口上都定义 try catch,接口数量一多将难以维护,所以需要一个服务端全局异常捕获。
不过目前 Nuxt3 还不支持捕获服务端的异常,这里是官网说明。所以该功能暂时未实现,后续也有可能通过 Test 来测试接口可靠性,而不是全局捕获异常接口。
不过 Nuxt3 对客户端的错误处理做得比较好,有个演示示例。
后续功能
由于 content 模块,以及 Nuxt3 后端服务的一些限制,导致一些功能就暂未实现,后续再考虑引入其他方案来实现
- 接口计次
- 接口分类
- 代码示例
- ip 白名单
收集接口
就此整个项目的核心功能就已经实现完毕了,接下来要做的就是收集 api 接口,写 api 文档了。然而这部分也是最头疼的部分,因为在互联网上很难有免费的资源。
像大部分的 api 接口,如果数据来源不是自己的,名义上“免费”的,那大概率就是有限制,例如一天只能 100 条,1 分钟只能请求几次等等,而且这类接口多半是需要填写一个 app_ey 的参数。而需要登录才能获取,当然,你可以选择加钱来增加限额,那么就不再是免费的了。总之就是各种不方便
如果真想实现免费无限制,那么数据来源只能在自己身上,至于数据来源如何转化成自己的,懂得都懂好吧。
所以在本项目仅可能的收集一手文档的资源接口或是自行封装的功能接口,但也会存在一些调用别人封装过的接口,服务端的接口信息可自行在server/api中查看,由于一些接口的安全性而言,线上的部分接口代码并未公布,这很正常,因为我并不想泄露一些关键数据。
如果接口调用有涉及侵权相关的还请直接联系作者删除。
部署项目
本地打包
npm run build
等待打包完毕,将打包后生成的.output 文件夹放到服务器上(依赖都无需安装,.output 文件里有 node_modules),执行
node .output/server/index.mjs
即可运行项目,或者也可以使用 pm2,总之和常见的 node 部署没什么差异。
此外也可部署到云提供商,像 AWS,Netlify,Vercel 等,所支持的服务商
坑点
打包失败
cherrio 中的 parse5 包无法打包至生成环境,提示如下
WARN Could not resolve import "parse5/lib/parser/index.js" in ~\.pnpm\hast-util-raw@7.2.1\node_modules\hast-util-raw\lib\index.js using exports defined in ~\parse5\package.json.
我猜测是因为 hast-util-raw 包和 cheerio 的 parse5 冲突,而 nuxt 服务端的 nitro 在用 rollup 打包时没有将两者冲突部分合并,而是选择前者,这就导致生产环境下 cheerio 无法使用。我尝试搜索没有得到一个很好结果,而我的解决方案是降级 cherrio 版本至 0.22.0,因为这个版本中没有引入 parse5。
版本切换
在我最终准备上线的时候,发现 nuxt 又有新版本了,于是我将项目从 rc.4 升级到 rc.6,然后再次测试的时候,发现在动态路由页面切换的时候,无法正常的向后端发送请求,甚至都监听不到路由变化,相当于页面被缓存了。
其实这也侧面说明了,目前 Nuxt3 的兼容性是比较差的。
实际上还有一些,不过解决相对比较迅速,就没写上。
总结
体验了一周的 Nuxt3,整个的开发过程不敢说特别顺利,因为存在一定的兼容和 Bug。目前 Nuxt3 的目前还处于 rc 版,实际项目还得考虑上线。不过个人还是非常推荐 Nuxt 这个框架,在代码编写与开发体验上实在是太香了,不出意外后续的 web 项目都会采用 Nuxt3 来构建,期待正式版的发布。